基于 Prometheus 的微服务监控指南
监控系统
随着微服务架构的广泛应用,现代软件系统的复杂性不断增加,对于系统监控和故障排除也更加困难。
在微服务架构中,每个服务都是独立运行的,需要对大量的服务进行监控。
且研发几乎不可能对系统存在的风险有100%的认知,即使做到了100%的认知,也不可能对所有风险环节做了100%容错,有效预警可以帮助研发及时发现系统中潜在的bug。
一个有效的监控系统成为保证微服务高可用、稳定性、可靠性的关键因素。
监控系统可以提供以下几个方面的帮助:
- 实时监测服务的健康状态和性能指标,以便及时检测和排除故障。
- 收集各个服务的指标数据,用于分析和优化系统性能。
- 对所有服务的监控数据进行统一管理和可视化展示,方便了解整个系统的情况。
本文将介绍如何使用Prometheus对golang微服务进行监控。
Prometheus
Prometheus 是云原生计算基金会项目,用于对系统或服务进行监控。它按给定的时间间隔从配置的目标服务收集指标信息,评估规则表达式、显示结果、观测指标达到指定条件时触发告警。
Prometheus 的主要特性:
- 多维数据模型(由指标名称和键/值集合组成的时间序列)
PromQL一种强大而灵活的查询语言,可以充分利用这种多维度数据- 不依赖于分布式存储;单个服务器节点是自治的
- 采用
HTTP拉取模型进行时间序列收集 - 支持通过中间网关推送批处理任务的时间序列
- 可以通过服务发现或静态配置发现目标服务
- 支持多种图形和仪表板展示模式
- 支持分层和水平联邦集群扩展
其他信息可查看 Prometheus 概述
Prometheus 架构图
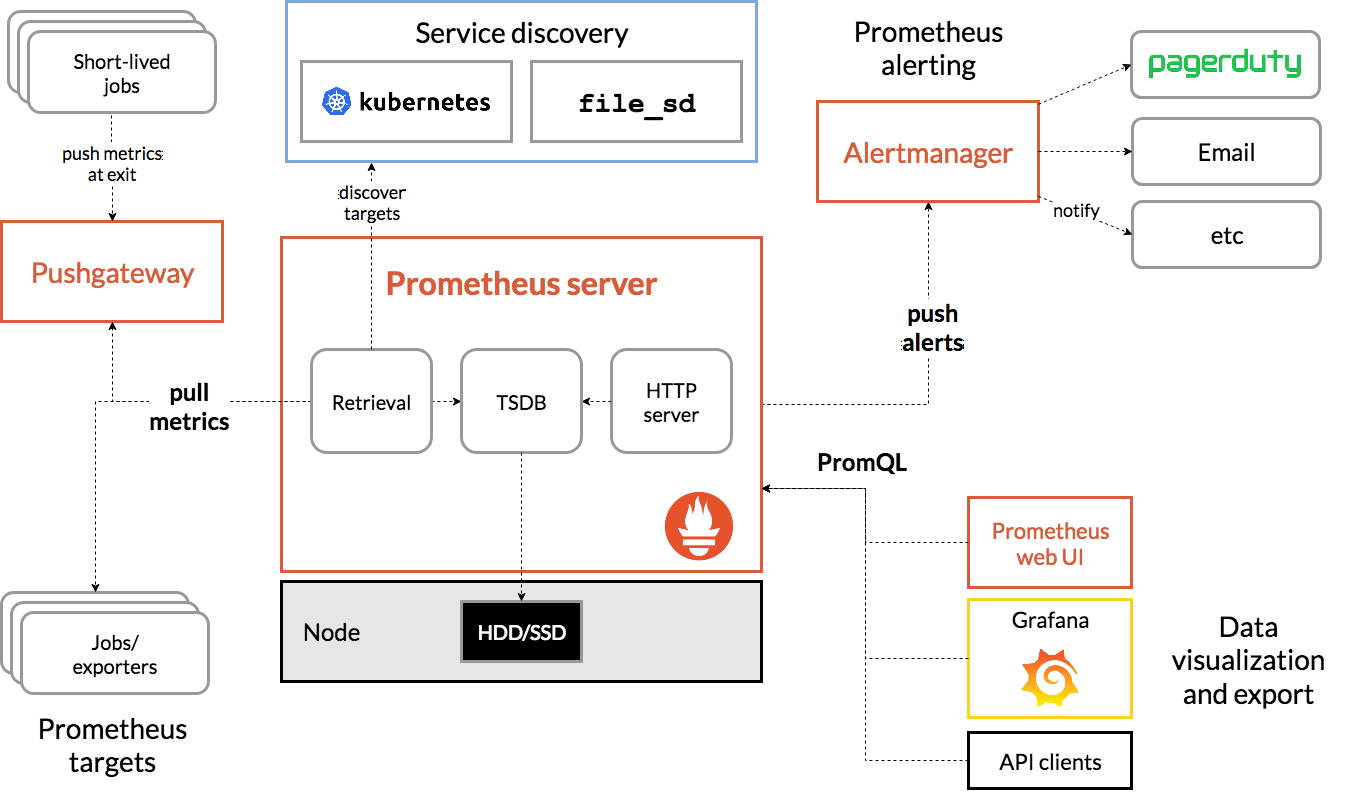
Prometheus 采集数据有两种方式:
- 一种是直接采样仪表化任务(instrumenting job)
- 另一种通过中介
push gateway来采样短时任务。
Prometheus 在本地存储所有采样的样本,同时基于这些数据进行规则计算、聚合数据和记录现有数据的新时间序列或者生成告警信息。收集的数据可以使用 Grafana 等其他工具进行可视化呈现。
Prometheus 支持多种服务发现,主要分为三类:
- 基于静态文件配置的服务发现
- 基于
HTTP的动态服务发现(consul、dns、dockers、kubernetes等多种) - 推送网关(Push Gateway)
在 Prometheus 术语中,可以抓取的服务称为实例(instance),通常对应于单个进程。具有相同目的的实例的集合,例如为了可扩展性或可靠性而复制的进程,称为作业(Job)。
适用场景
Prometheus 非常适合记录任何纯数字时间序列。它既适合以机器为中心的监控,也适合高度动态的面向服务的架构的监控。在微服务的世界中,它对多维数据收集和查询的支持是一个特殊的优势。
Prometheus 的设计注重可靠性,当出现服务中断或故障时,可以依赖它来快速进行问题诊断。每个 Prometheus 服务器都是独立的,不依赖于网络存储或其他远程服务。当基础设施的其他部分损坏时,依然可以依赖它进行问题分析,并且无需设置大量基础设施即可使用它。
不适用的场景
Prometheus 重视可靠性。即使在出现故障的情况下,也可以随时查看有关系统的可用统计信息。但是如果需要 100% 的准确性,例如按请求计费、每一笔订单的信息时,Prometheus 不是一个好的选择,因为收集的数据可能不够详细和完整。在这种情况下,您最好使用其他系统来收集和分析计费数据,并使用 Prometheus 进行其余功能的监控。
数据模型
Prometheus 收集由指标名和标签键值对组成的数据,作为时间序列进行存储。
指标和标签
指标名称: 只能包含 ASCII 字母、数字、下划线和冒号。必须符合正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]* 。
标签名称: 只能包含 ASCII 字母、数字和下划线。必须符合正则表达式 [a-zA-Z_][a-zA-Z0-9_]* 。以 __ (两个 _)开头的标签名称是保留内部使用。
标签值: 可以包含任何 Unicode 字符
指标名和标签名命名规范:https://prometheus.io/docs/practices/naming/
时间序列
每个时间序列都由指标名称和可选的标签键值对唯一标识。
Prometheus 将所有指标数据存储为时间序列:即属于同一指标和同一组标签的带时间戳的数据流。
时间序列格式:<metric name>{<label name>=<label value>, ...}
如:api_http_requests_total{method="POST", handler="/messages"}
指标类型
Counter
计数器是一种累计指标类型,表示一个单调递增计数器。其值只能递增或在重启时重置为零。
通常用于表示所服务的请求数、已完成的任务数或错误数。
Gauge
仪表代表一种值可以任意增加和减少的单个数值的指标类型。通常用于表示温度变化或内存使用情况等,但也用于可增加可减少的“计数”,如并发请求数。
Histogram
直方图对观测结果(通常是请求持续时间或响应体的大小)进行采样,并将计数记录到可自定义配置的存储桶中。同时还保存了所有观察值的总和。
在抓取期间,直方图在指标名称的基础上产生三个指标(时间序列):
- 观测桶的累积计数指标,格式为:
<basename>_bucket{le="<upper inclusive bound>"}; - 观测值的总和,格式为:
<basename>_sum - 观测值的个数,格式为:
<basename>_count(等同<basename>_bucket{le="+Inf"}的值)
使用 histogram_quantile 函数计算直方图的分位数或者仅用于聚合直方图。
注:
le 含义: less or equal
Summary
与直方图类似,摘要对观察结果进行采样(通常是请求持续时间和响应大小等)。同时它还提供了观察值总数量和所有观察值的总和,还可以通过滑动时间窗口计算可配置的分位数。
在抓取期间,摘要在指标名称的基础上产生三个指标(时间序列):
- 基于连续的时间序列计算φ-分位数(0 ≤ φ ≤ 1),格式为:
<basename>{quantile="<φ>"} - 观测值的总和,格式为:
<basename>_sum - 观测值的个数,格式为:
<basename>_count
使用直方图和摘要可以计算所谓的 φ 分位数,其中 0 ≤ φ ≤ 1。 φ 分位数是指在 N 个观测值中排名第 φ*N 的观测值。 φ 分位数示例: 0.5 分位数称为中位数。 0.95 分位数是第 95 个百分位数。
摘要和直方图之间的本质区别在于,摘要在客户端计算时序数据的 φ 分位数并直接导出到服务端,而直方图则是导出桶里观测计数,服务端使用 histogram_quantile() 函数计算分位数。
这两种方式有许多不同点:
| Histogram | Summary | |
|---|---|---|
| 所需的配置 | 选择适合观测值预期范围的桶配置。 | 选择所需的 φ 分位数和滑动窗口。观测数据无法计算其他 φ 分位数和滑动窗口。 |
| 客户端性能 | 只需要增加计数器,性能成本低。 | 需要计算时序数据的分位数,性能成本高 |
| 服务端性能 | 服务器计算分位数。如果临时计算花费太长时间(例如在大型仪表板中),可以使用记录规则。 | 服务器端性能成本低。 |
| 时间序列数(除了_sum和_count之外) | 每个配置的存储桶是一个时间序列。 | 每个配置的分位数是一个时间序列。 |
| 分位数误差 | 相关数据桶(bucket)的宽度决定误差值 | 可配置的φ值决定误差值 |
| φ 分位数和滑动时间窗 | 与具体 Prometheus 表达式相关 | 由客户端预先配置 |
| 聚合操作 | 与具体 Prometheus 表达式相关 | 通常不能进行聚合 |
直方图适合场景:
- 服务端对不同服务、不同标签进行聚合计算
- 时序数据数量级比较大,比较消耗资源时
- 可接受数据计算时的精度损失
摘要图适合场景:
- 不需要服务端聚合操作
- 客户端可以接受性能消耗
- 需要准确的分位数数据(直方图计算时会进行线性插值)
PromQL
Prometheus 提供了一种名为 PromQL(Prometheus Query Language)的功能查询语言,可以让用户实时选择和聚合时间序列数据。表达式的结果可以显示为图表,在 Prometheus 表达式浏览器中以表格数据形式查看,或者由外部系统通过 HTTP API 使用(如 Grafana)。
PromQL 支持子查询语句。
rate(http_requests_total[5m])[30m:1m]
max_over_time(deriv(rate(distance_covered_total[5s])[30s:5s])[10m:])
PromQL 支持以 # 开头的行注释。
PromQL语言数据类型
瞬时向量(Instant vector): 给定时间戳上的一组时间序列,每个时间序列包含一个样本值。(样本值由一个指标名、一个样本值和多个标签组成)
范围向量(Range vector): 给定时间范围上的一组时间序列,每个时间序列包含该段时间内的样本值。
标量(Scalar): 一个简单的浮点值
字符串(String): 一个简单的字符串值;目前未启用
时间序列选择器
瞬时向量选择
-
按给定时间戳(即时)选择一组时间序列和每个时间序列的单个样本值 最简单的形式:
http_requests_total -
可以通过在大括号 ( {} ) 中使用逗号分隔的标签匹配列表过滤时间序列 使用标签过滤:
http_requests_total{job="prometheus",group="canary"} -
向量选择器必须指定一个名称或至少一个与空字符串不匹配的标签匹配器
{job=\~".\*"} # Bad! 匹配了空标签字符串值
{job=~".+"} # Good! 未匹配空标签字符串值
{job=~".*",method="get"} # Good! 未匹配空标签字符串值
- 内置标签名
__name__表示指标名称{__name__="http_requests_total",job=~".+"}
查询时,标签名称不能使用关键字,但是可以使用 __name__ 标签名来使用关键字
关键字: bool, on, ignoring, group_left and group_right
{__name__="on"} # Good! 通过 __name__ 使用标签名是关键字标签
-
标签匹配运算符
-
=: 选择与指定的字符串完全相等的标签 !=:选择与指定的字符串不相等的标签=~:选择与指定的字符串满足正则表达式匹配的标签!~:选择与指定的字符串不满足正则表达式匹配的标签
范围向量选择
在瞬时向量选择器后使用方括号[]来指定范围向量的时间范围,时间范围是闭区间。
指标 http_requests_total 且 job 为 prometheus 的指标过去5分钟内的范围向量值:
http_requests_total{job="prometheus"}[5m]
时间格式
- ms 毫秒
- s 秒
- m 分钟
- h 小时
- d 天
- w 周
- y 年
时间可以串联组合,单位必须按照从最长到最短的顺序排列,同一个单位只能出现一次。
Offset 修饰符
offset 修饰符允许更改查询中各个瞬时向量和范围向量的时间偏移,offset 修饰符始必须紧跟在选择器后面。
http_requests_total offset 5m # 相对于现在 5 分钟前的向量值
sum(http_requests_total{method="GET"} offset 5m) // GOOD.
sum(http_requests_total{method="GET"}) offset 5m // INVALID. 必须紧跟向量选择器
rate(http_requests_total[5m] offset 1w) # 同样适用于范围向量,一周前
rate(http_requests_total[5m] offset -1w) # 同样适用于范围向量,一周后
@ 修饰符
@ 修饰符允许更改查询中各个瞬时向量和范围向量的时间戳,时间格式为 unix 时间戳,内部使用浮点数表示。@ 修饰符始必须紧跟在选择器后面。
http_requests_total @ 1609746000 # 2021-01-04T07:40:00+00:00 的指标值
sum(http_requests_total{method="GET"} @ 1609746000) # GOOD.
sum(http_requests_total{method="GET"}) @ 1609746000 # BAD.
rate(http_requests_total[5m] @ 1609746000) # 适用于范围向量 2021-01-04T07:40:00+00:00 的指标值
@ 修饰符可以和 Offset 修饰符一起使用,表示在 @ 修饰符指定的时间上进行 Offset 偏移,结果和这两个修饰符的顺序无关。
# 以下两种形式相同
# offset after @
http_requests_total @ 1609746000 offset 5m
# offset before @
http_requests_total offset 5m @ 1609746000
start() 和 end() 内置函数可以搭配 @ 修饰符使用
- 对于瞬时查询,
start()和end()都解析为表达式计算的时的时间。 - 对于范围查询,分别解析为范围查询的开始和结束时间。
操作符和函数
操作符列表和示例:https://prometheus.io/docs/prometheus/latest/querying/operators/
函数列表和示例:https://prometheus.io/docs/prometheus/latest/querying/functions/
示例
查询语句示例:https://prometheus.io/docs/prometheus/latest/querying/examples/
Alertmanager
Alertmanager 处理应用程序(例如 Prometheus 服务器)发送的告警。
Prometheus 的告警功能分为两部分。Prometheus 按服务中的告警规则将告警发送到告警管理器;然后,Alertmanager 管理这些告警,包括沉默、抑制、聚合以及通过电子邮件、通知系统和聊天平台等方式发送通知。
Alertmanager 支持创建集群以实现高可用性,但是不要在 Prometheus集群 和 Alertmanager 集群做负载均衡,要在 Prometheus 里配置所有的 Alertmanagers 列表。因为同一警告可能被发送到不同的 Alertmanager,导致警告的处理不一致。
Grouping(分组)
分组将相似的告警合并为单个通知。服务大规模停机的场景会很有用,此时许多系统同时发生故障,可能触发数百到数千个告警。
Inhibition(抑制)
抑制是在某些特定告警已经触发的情况下抑制某些告警的通知。可以阻止大量与实际问题无关的告警通知。
Silences(静默)
静默是在特定时间内不发送告警。Alertmanager 检查收到的告警是否与静默配置匹配,如果匹配,则不会发送该告警的任何通知。
可视化
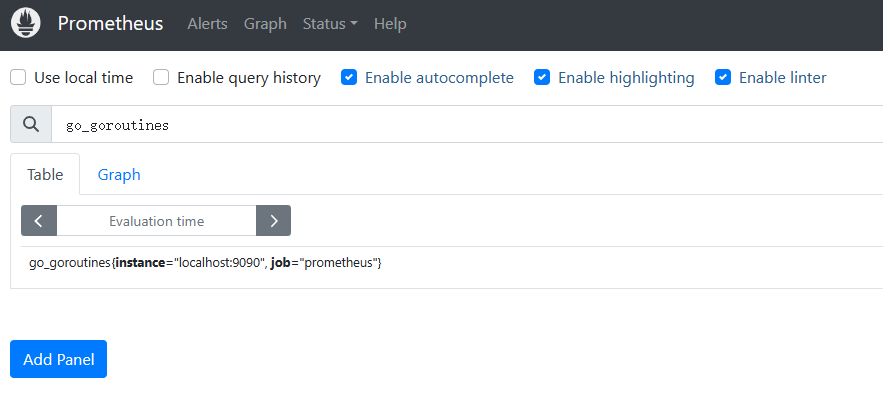
表达式浏览器
表达式浏览器是 Prometheus 服务自带的指标展示功能,通过 Prometheus 服务地址+ /graph访问,允许输入任何表达式并以表格或图表形式查看结果。
如:http://127.0.0.1:9090/graph
Grafana
Grafana 是开源可视化和分析软件。支持查询、可视化、警报指标、日志和跟踪,无论它们存储在何处。它为您提供了将时间序列数据库 (TSDB) 数据转换为富有洞察力的图表和可视化的工具。
- 数据源: Grafana 支持多种不同的数据源,包括 Prometheus、InfluxDB、Elasticsearch、MySQL 等。用户可以轻松将其数据导入到 Grafana 中进行可视化。
- 仪表盘: Grafana 提供了一个灵活易用的仪表盘编辑器,可让用户创建自定义的可视化图表和面板。这些仪表盘可以根据需要自由布局,并且可以轻松地嵌入到其他应用程序或网站中。
- 查询: Grafana 具有强大的查询功能,可以帮助用户快速检索和分析数据。查询语言包括 SQL、PromQL 等。
- 可视化: Grafana 提供了多种数据可视化选项,包括图表、表格、地图、单值指标等。
- 警报: Grafana 还支持警报功能,可以通过电子邮件、Slack、PagerDuty 等渠道向用户发送警报,并在发生事件时通知用户。
监控服务指标实战
通常需要监控的指标类别有:
业务指标: 业务指标可以直观的反馈业务或者系统功能是否正常可用,常用的指标有业务请求吞吐量、业务成功率。
服务指标: 服务指标是指能够反馈业务依赖的服务是否可用的指标,统计的指标类型类似于业务指标,只不过是接口维度,同样可以分为吞吐量、成功率以及性能。
环境指标:环境指标也是资源指标,用来反馈底层基础设施或者依赖服务可用率。如使用率、可用性、性能等。
环境指标通常由基础组件服务本身支持或者第三方库支持,在 Prometheus 概念中称作 exporters
支持的第三方服务 exporters 列表:https://prometheus.io/docs/instrumenting/exporters/
以下介绍如何进行业务和服务的指标监控,以 golang 语言为例。
注册指标
需要监控的指标需要先在代码中定义,然后通过不同语言的 SDK 进行注册
以下是收集服务的每个接口的响应时间的指标定义和注册方式:
package server
import "github.com/prometheus/client_golang/prometheus"
// 定义指标
var (
namespace = "airline"
subsystem = "booking"
_metricSeconds = prometheus.NewHistogramVec(prometheus.HistogramOpts{
Namespace: namespace,
Subsystem: subsystem,
Name: "grpc_server_handling_seconds",
Help: "Histogram of response latency (seconds) of gRPC that had been application-level handled by the server.",
Buckets: prometheus.DefBuckets,
}, []string{"kind", "operation"})
)
// 注册指标
func init() {
prometheus.MustRegister(_metricSeconds)
}
Namespace: 指标所属的命名空间,通常为业务分类,使用单个单词表示。 Subsystem: 指标所属的子系统,通常为业务内部服务名,使用单个单词表示。 Name: 指标名称
其中 Namespace 和 Subsystem 是可选项。
指标名称拼接规则:
func BuildFQName(namespace, subsystem, name string) string {
if name == "" {
return ""
}
switch {
case namespace != "" && subsystem != "":
return strings.Join([]string{namespace, subsystem, name}, "_")
case namespace != "":
return strings.Join([]string{namespace, name}, "_")
case subsystem != "":
return strings.Join([]string{subsystem, name}, "_")
}
return name
}
指标名和标签名命名规范参考:https://prometheus.io/docs/practices/naming/
暴露指标收集接口
为了能够让 Prometheus 服务采集到服务收集的指标,需要暴露出 /metrics HTTP 接口
,并且使用 prometheus/promhttp 库的 HTTP Handler 作为处理函数。
import "github.com/prometheus/client_golang/prometheus/promhttp"
func Register(srv *http.Server){
srv.Handle("/metrics", promhttp.Handler())
}
Prometheus 根据配置的采集间隔,定时从服务拉取指标数据。
收集到的指标数据可通过可视化工具进行图形绘制和告警配置。
注意事项
-
明确采集目标,设置正确的指标
-
避免过度监控
过多的指标会占用大量存储,且导致查询缓慢
- 标签值必须是有限值的集合
每个不同标签键值对集合都代表一个不同的时间序列,如果标签值是任意值,会明显增加存储的数据量。标签值不能是用户ID、订单号、电子邮件等有无限个不同值的数据。
- 无法用于准确值统计的场景
Prometheus 采集到数据可能是不完整的
参考资料: